Architecture¶
This page describes how a write from a pod travels through MeshStor to a sector on disk, layer by layer. For the components that maintain that data path — the controller StatefulSet, the node DaemonSet, the reconciliation loop, and the custom resources — see Internals.
MeshStor delivers replicated block storage using only kernel subsystems: GPT partitions on NVMe drives, NVMe-oF for network transport, and MD RAID for replication. Every byte travels from pod to disk through kernel code paths — no userspace proxies, no protocol translation, no custom replication engines.
The Data Path¶
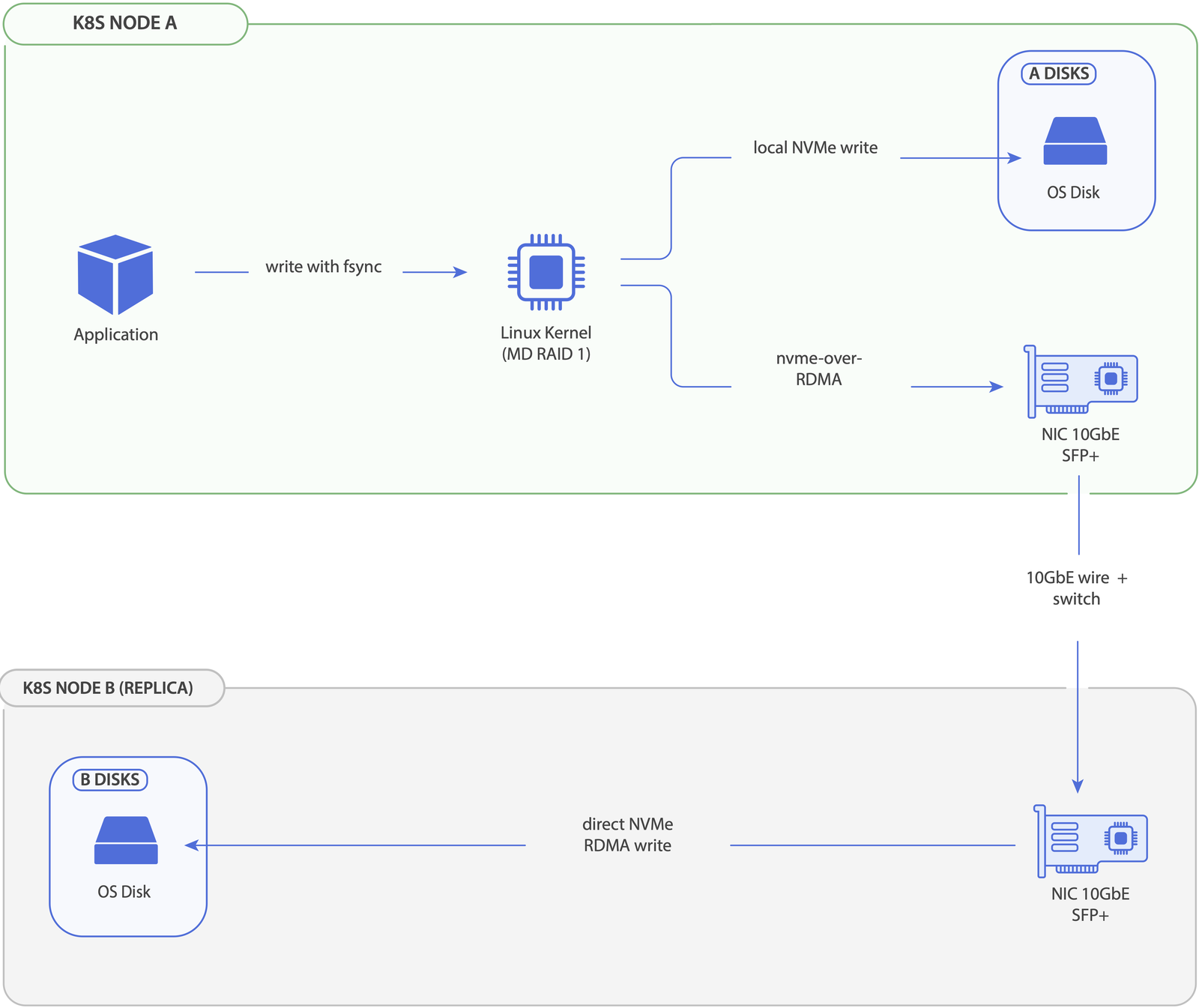
Writes go to every replica in parallel — the local member directly to block device, remote members via NVMe-oF — and complete when the slowest replica acknowledges. Reads bias toward the lowest-latency replica via a latency_ewma × (pending + 1) cost function (custom MeshStor kernel module behaviour); on the typical local + NVMe-oF setup this means the local block device handles steady-state reads and overflow goes to remote only when the local queue depth makes the costs comparable. The MD write-intent bitmap tracks which regions are dirty, so only changed blocks need resync after an interruption — not the entire volume.
Storage Layer: GPT Partitions¶
Volumes are real GPT partitions on physical NVMe drives — not files, not loopback devices, not thin-provisioned images, not LVM PV or LVM VG. Each volume gets a dedicated partition with a deterministic UUID derived from the volume name. Multiple volumes share a drive through the GPT partition table.
This means:
- Direct block device I/O — no filesystem-on-filesystem overhead, no copy-on-write tax
- 4 KiB logical sector size — the driver re-formats NVMe namespaces to 4K if no partitions on it
- Partition alignment to 1 MiB boundaries for optimal NVMe write performance
- Clean tenancy — new partitions are zeroed and superblocks cleared to prevent stale metadata from previous users
- XFS formatted with a per-volume UUID for consistent identification across reboots and node migrations
Transport Layer: NVMe-oF¶
Remote partitions appear as native NVMe block devices on the consuming node. The kernel's NVMe-oF initiator handles all data I/O — MeshStor only configures the connection at setup time.
| Transport | When Used | Latency | CPU Overhead |
|---|---|---|---|
| RDMA | Both nodes share an RDMA subnet | Lowest (~1 us network) | Near zero (kernel bypass) |
| TCP | Any IP network | Low (~10 us network) | Minimal (kernel TCP stack) |
Transport is selected automatically per node pair. When both nodes advertise an RDMA address, RDMA is used; if those addresses are written in CIDR notation, the two ends must share a subnet. Otherwise, TCP provides a capable fallback that works over any IP network without special hardware.
RDMA is where MeshStor shines most
TCP is a fully supported — no special hardware required — but RDMA (RoCEv2 on Ethernet, or InfiniBand) is recommended whenever the hardware supports it. It is the setup where MeshStor performs best: microsecond-class network latency and near-zero CPU on the replication path. See Prerequisites → Network to annotate nodes with an RDMA address.
Connection parameters are tuned for fast failure detection:
| Parameter | Value | Purpose |
|---|---|---|
| Keep-alive | 1s | Detect hung controllers quickly |
| Fast I/O fail | 1s | Fail I/O to MD for fast failover |
| Controller loss | 3s | Tear down connection if unrecoverable |
| Reconnect delay | 1s | Retry connection immediately |
Address configuration (TCP and optional RDMA annotations, required ports, and the subnet connectivity rule) lives in Prerequisites.
Replication Layer: MD RAID¶
Linux MD RAID mirrors writes across local and remote partitions. This is the same subsystem that has protected production Linux servers for decades — battle-tested, well-understood, and maintained by the kernel community.
| Replicas | Stripe width | RAID Level | Behavior |
|---|---|---|---|
| 1 | 1 | RAID1 (2 slots) | 1 active + 1 placeholder for relocation |
| 1 | 2 | RAID10 (placeholder mirrors) | RAID0-like throughput, placeholder slots keep the volume relocatable |
| 2 | 1 | RAID1 | Mirror across 2 nodes |
| 3 | 1 | RAID1 | Mirror across 3 nodes |
| 2 | 2 | RAID10 | Striped mirrors across 2 nodes, 2 drives each |
Key design choices:
- Write-intent bitmap — tracks dirty regions at block granularity. After a brief disconnection, only the changed blocks resync — not the entire volume. This turns a multi-hour rebuild into seconds or minutes.
- Assume-clean creation — new arrays skip the initial full sync because all members start empty. The first real data write is the only write.
- Latency-aware reads — MD picks the read target with the lowest
latency_ewma × (pending + 1)cost (custom MeshStor kernel module behaviour). On a typical local + NVMe-oF setup this directs steady-state reads to the local replica and overflows to remote only when local queue depth drives cost above the remote leg. MeshStor deliberately does not set--write-mostlyon remotes — the latency signal is enough. Sequential streams pin to one disk to avoid re-seeking. - Interleaved layout — for RAID10, partitions from different nodes alternate across mirror groups. No single node failure can take out an entire stripe.
See Replication for StorageClass configuration, degraded operation, and recovery behavior.
Self-Healing¶
MeshStor continuously monitors volume health through a reconciliation loop on every node. Recovery is automatic — no operator intervention required.
Automatic reconnection — if an NVMe-oF connection drops and recovers (transient network blip, node reboot), the kernel re-establishes the connection and MD resyncs only the dirty bitmap regions. For brief interruptions, resync completes in seconds.
Member replacement — if a partition stays unreachable beyond the configurable timeout (default 15 minutes, minimum 60 seconds), the reconciler selects the best available node and provisions a replacement partition. The new member syncs from the surviving replica, and the old member is cleaned up automatically.
Drain migration — when a node is drained with kubectl drain --ignore-daemonsets, the volume migrates transparently to the new node. The old partition is imported via NVMe-oF, a new local partition is created, MD syncs the data, and the old partition is removed. The pod sees no data loss and minimal interruption.
See Self-Healing for failure recovery and Volume Relocation for drain migration details.
Node Placement¶
When selecting which nodes host volume partitions, MeshStor scores every candidate node:
| Factor | Priority | Rationale |
|---|---|---|
| RDMA connectivity | Highest | Lower latency, lower CPU overhead on the data path |
| Network latency | High | Prefers topologically closer nodes |
| Available free space | Medium | Distributes volumes evenly, avoids capacity hotspots |
| Fault isolation | Enforced | One partition per node per volume — no single-node SPOF |
Cordoned and NotReady nodes are excluded from new placement — draining a node is therefore sufficient to stop new partitions from landing on it. When an MD array has an excess member and must shed one (for example, after a drain migration finishes and the old remote partition is no longer needed), MeshStor preferentially evicts members sourced from cordoned or unhealthy provider nodes.
The scoring runs at volume creation and again when replacing a failed member, ensuring optimal placement adapts to the current cluster state. When a chosen node has multiple eligible drives, the driver picks the one with the most free space, so volumes spread across drives rather than piling onto a single one.
Failure domains¶
Each layer of the data path protects against a specific failure class. The table below shows which layer catches what.
| Failure | Caught by | What survives |
|---|---|---|
| Bad disk sector | MD RAID read-repair + periodic scrub | All replicas. MD detects the bad block on read, serves the data from a good mirror, and rewrites the sector in place. |
| Drive failure | MD marks the affected partitions Faulty; reconciler replaces them after memberMissingTimeout |
N − 1 replicas still serve I/O. |
| Node failure | NVMe-oF host driver disconnects → reconciler marks the remote member Missing and replaces it after memberMissingTimeout |
N − 1 replicas still serve I/O. |
| Network partition | Same as node failure, but for every unreachable node | Consumer keeps serving I/O from its local replica; redundancy temporarily drops to N − (cut-off replicas) until replacements sync. |
| Simultaneous loss of all replicas | CSI driver evicts the pod so Kubernetes can reschedule it | No data loss if at least one replica comes back; the pod resumes as soon as at least one replica become available. |
The replica count (replicaCount) is the dominant variable for availability: two replicas survive any single failure, three replicas survive any two simultaneous failures. replicaCount=1 has no hardware redundancy, but it still survives a soft eviction of the pod — MeshStor relocates the partition to another node before the eviction takes effect. See the local-storage section of Comparison for the argument.
For the timeline of how MD detects and responds to each failure class, see Self-Healing.
I/O characteristics¶
A write to a replicaCount=N volume fans out to every replica: 1 local block write to the consumer node's drive plus N − 1 NVMe-oF writes to remote partitions. Reads load-balance across all replicas. The arithmetic for an evaluator's mental model:
| Property | Value | Notes |
|---|---|---|
| Backing-device write IOPS | N × volume IOPS | Each volume write hits all N replicas |
| Backing-device write throughput, per replica | volume throughput | Mirroring writes the same bytes to each replica |
| Pod-observed write latency | max(local, remote_1, …, remote_{N−1}) |
Replicas are written in parallel; the slowest member sets the floor |
| Pod-observed read latency | local-drive latency in steady state | MD picks the read target by latency_ewma × (pending + 1) cost (custom MeshStor kernel module behaviour); reads overflow to remote replicas only when the local queue depth makes costs comparable. Sequential streams pin to one disk. |
replicaCount=1 collapses all multipliers to 1 — same data path as a replicated volume, but only the local partition is written. No remote NVMe-oF traffic in steady state.
stripeWidth > 1 (RAID10) spreads each replica across stripeWidth drives at a 64 KiB chunk granularity. Each drive sees 1/stripeWidth of the volume's bytes, which raises the per-replica throughput ceiling. The IOPS picture depends on application I/O size: writes that fit inside one chunk hit replicaCount backing drives (no stripeWidth multiplier — striping just chooses which drives), while writes that span K chunks are split by MD and produce K × replicaCount backing IOPs. Volume capacity grows as stripeWidth × replica capacity. See Replication for the RAID-level detail.
What you'll find on related pages¶
This page covered the data path — how a write physically reaches a sector on disk. Related pages cover adjacent topics:
- Internals — the components that operate the data path: controller StatefulSet, node DaemonSet, reconciliation loop, custom resources
- Replication — MD RAID semantics, degraded operation, resync behavior
- Performance — overhead analysis of the data path described above
- Self-Healing — how the system responds to network partitions and node failures